Edit me
By koosy on 2015.05.19
@inproceedings{jia2014caffe,
title={Caffe: Convolutional architecture for fast feature embedding},
author={Jia, Yangqing and Shelhamer, Evan and Donahue, Jeff and Karayev, Sergey and Long, Jonathan and Girshick, Ross and Guadarrama, Sergio and Darrell, Trevor},
booktitle={Proceedings of the ACM International Conference on Multimedia},
pages={675--678},
year={2014},
organization={ACM}
}
Abstract
caffe는 최신 딥러닝 알고리즘과 모델들을 포함하는 수정 가능한 소프트웨어 프레임워크 입니다. BSD 라이센스의 C++ 라이브러리와 파이선 및 메틀렙 바인딩 툴을 포함하며, convolutional neural networks (CNN) 및 기타 딥러닝 모델을 효율적으로 구성하고 학습할 수 있습니다. caffe는 CUDA GPU 프로세싱을 지원하며, K40 또는 Titan GPU를 사용하면 4천만장의 이미지를 하루에 처리할 수 있습니다. 실제 코드 구현과 모델정의를 분리함으로써 실험 및 플렛폼간 매끄러운 변환을 가능하게 하며, 이는 프로토타이핑 머신에서부터 클라우드 환경에 이르기까지 개발 및 배포에 용이합니다.
caffe는 Berkeley Vision and Learning Center (BVLC)에 의해 개발되었고 GitHub 기여자들에 의해 유지되고 있습니다. caffe는 연구과제, 대용량 산업응용, 비젼/음성/영상 처리 관련 스타트업에 활용될 수 있습니다.
아래는 요약만 할게요. 어설픈 번역보다 원문을 보시는게 더 이해하시기 좋을듯...
Introduction
- 이미지, 음성신호, 햅틱신호 등 센서 정보를 효과적으로 표현하기 위해 딥모델들이 수작업 특징 추출보다 뛰어난 성능을 발휘하였다. 특별히 대용량 비전인식 분야에서 CNN이 성공적으로 동작하였다.
- 하지만, 출판된 성공적인 연구결과를 재활용 하는데는 수개월이 걸리고, 연구자들은 논문 외에도 학습한 모델을 배포하는것이 실제 그 결과를 활용하는데 더 가치있다고 여기게 되었다. 이렇게 미리 학습된 모델을 이용하기 위해서는 효율적인 계산이 가능한 툴이 필요하다.
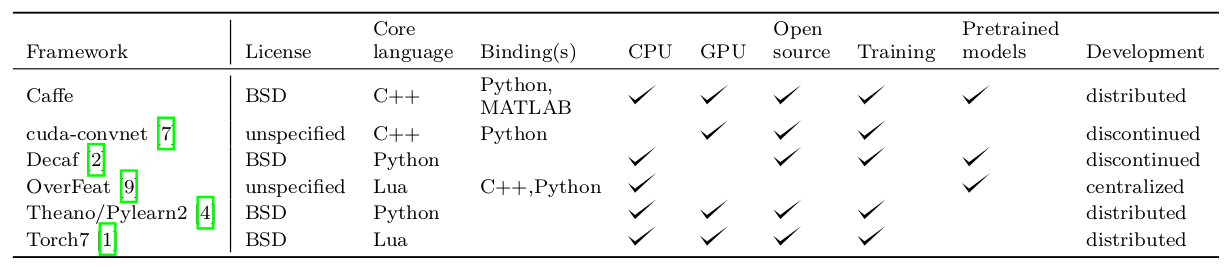
- 이를 목적으로 caffe는 오픈소스 플렛폼, C++, CUDA GPU연산, Python/Numpy 및 Matlab을 지원한다.
- 특징: 유닛 테스트, 엄격하고 빠른 배포, 모듈화된 코드, 네트워크 정의와 실제 구현간의 엄격한 구분.
- 활용영역: 비젼 및 음성 인식, 로보틱스, 뉴로사이언스 등
Highlights of caffe
caffe는 네트워크 모델의 학습, 테스트, 튜닝, 배포를 위한 완성된 툴킷을 지원한다. 연구자들 및 개발자들이 최신 머신러닝의 세계로 뛰어들기에 이상적인 시작점이다. 동시에 산업현장에서 즉시 쓰일 수 있도록 현존하는 가장 빠른 성능을 가진 알고리즘들이 구현되어 있다.
- Modularity: 새로운 데이터 포멧, 네트워크 레이어, loss function 등에 쉽게 확장 가능하도록 모듈화되어 개발됨.
- Separation of representation and implementation: 네트워크 모델은 Protocol Buffer 언어를 이용한 config files 로 정의됨. directed acyclic graph 형태의 임의의 네트워크 정의 가능 (Recurrent는 안되네요. 참고하시길..) CPU 또는 GPU 구현은 function 하나만 부름으로써 변환 가능.
- Test coverage: 각 개별 모듈은 각 test code를 가지고 있음. (처음 make 할 때 test code 동작을 확인할 수 있습니다. 또한 각 모듈화된 test code를 공부함으로써 caffe의 각 모듈 기능 사용법을 배울 수 있습니다.)
- Python and Matlab bindings: 기존 코드들과의 인터페이싱을 위해 python/matlab binding을 지원합니다. 네트워크를 구성하거나 입출력 뿐 아니라 python binding은 solver module에 접근함으로써 새로운 훈련과정을 구성할 수 있습니다. (이거 탐나는 기능이네요. 누구 python 잘 하시는 분께서 알려주시면 좋을 듯 합니다.)
- Pre-trained reference models: 비젼인식에 관한 참고모델(AlexNet ImageNet, R-CNN detection model) 제공 (BSD license 아님)
Architecture
Data storage
- blob 이라고 하는 4차원 배열을 사용하여 데이터를 저장하고 모듈간 통신함
- blob은 메모리 인터페이스를 제공하며, CPU/GPU간 동기화 및 이종 연산에 대한 고민을 하지 않도록 한다. (제 경험상 동기화에 꽤 많은 계산 시간을 요구하기 때문에 고민을 좀 하긴 해야 합니다. 그래도 고려만 할 뿐 실제 구현은 안해도 되니 편합니다.) 메모리는 요청에 의해 할당됨.
- 모델은 Google Protocol Buffers 에 의해 저장됨. protobuf의 특징: 최소사이즈 바이너리 스트링, 효율적인 시리얼화, text format 등등 (써보니 xml 보다 장점이 많습니다.)
- 대용량 데이터셋은 LevelDB에 저장됨.
Layers
- 하나 또는 다수의 blob을 입력으로 하고, 하나 또는 다수의 blob을 출력으로 하는 네트워크의 구성 단위.
- forward pass: 입력 --> 출력
- *backward pass: 출력의 구배(gradient)를 통해 layer의 파라미터들의 증감(gradient)를 계산. 최종 출력의 오차를 역전파 (back probagation) 함.
- convolution, pooling, inner products, rectified linear, logistic, local response normalization, element-wise operations, losses like softmax and hinge 등의 형태를 가지는 layer 제공.
Networks and Run Mode
- caffe network는 디스크로부터 data를 로딩하는 data layer부터 목적(오류)함수를 계산하는 loss layer까지 하나의 네트워크로 구성된다.
- 이 네트워크는 CPU 또는 GPU에서 동작하며, 이는 하나의 switch로 세팅할 수 있다. 두 모드는 동일한 결과를 출력한다. 이는 모델 정의와는 독립적으로 동작함.
Training a network
- caffe는 빠르고 표준인 stochastic gradient descent algorithm 으로 모델을 훈련한다. 아래 그림은 MNIST digit classification 을 위한 네트워크 모델의 한 예이다. (투토리얼에서 예제로 다룰 예정입니다.)

- 데이터 레이어는 각 이미지와 라벨을 읽어오고, 영상 데이터는 convolution, pooling, rectified linear transforms 등의 멀티 레이어를 거쳐서 라벨과 비교하여 오류값을 생성하는 loss layer에 도달한다. 그리고 그 오차의 구배(gradient)를 통해 전체 네트워크를 훈련하게 된다.
- 네트워크 훈련을 위한 파라미터는 learning rate decay schedules, momentum, stopping 및 resuming을 위한 snapshots 등이 있으며, 모두 구현되어 있고 문서화 되어 있다.
- Finetuning 은 기존 훈련된 모델을 새로운 아키텍쳐나 데이터에 적용하는데 사용된다. 기존 네트워크의 snapshot 과 새로운 네트워크 정의로부터 새로운 테스크에 대한 모델 파라미터들(weights)을 튜닝한다. 이 기능은 knowledge transfer, object detection, object retrieval 등에 활용된다.
Applications and examples
- Object classification. online demo: 1,000 ImageNet 카테고리 중에서 하나 맞추기. 또한 이렇게 학습된 네트워크를 finetuning 해서 10,000 개의 full ImageNet 카테고리를 구분하였다. (헐..)
- Learning semantic features. 미리 학습된 네트워크를 이용하여 semantic feature를 추출하는데 사용됨 [DeCaf]. 이 피쳐는 또한 다른 스타일의 이미지 (빈티지 또는 로맨틱) 를 구분하는데에도 의미있는 결과를 보임.
- Object detection. 현재까지 사물검출에 가장 탁월한 성능을 보임. (PASCAL VOC 2007-2012, ImageNet 2013 Detection challenge)