다섯번째 예제에서는 Layer를 이용하여 Logistic Regression Model을 구현해보고 MNIST 데이터를 통해 학습하고 라벨을 예측해봅니다.
Edit me
By koosy on 2016.1.7
Logistic Regression Classification with MNIST dataset using 'layer' in Caffe
지난 시간까지 Caffe의 기본 구조인 Blob, Layer에 대해 알아보았습니다. 그리고 앞으로 자주 사용하게 될 MNIST 데이터셋에
대해서도 살펴보았습니다. 이번 시간부터는 본격적으로 네트워크 모델을 학습하고 주어진 데이터의 라벨을 예측하는 교사학습 (supervised
learning)을 Caffe를 이용하여 구현해 보겠습니다.
supervised learning, unsupervised learning, classification, regression 등 머신러닝에
대한 기본적인 용어 설명은 생략합니다. 딥러닝을 위한 머신러닝 기초는 Bengio 그룹의 Deeplearning Book를 추천합니다.
Online Linear Regression
이번에 구현할 모델은 Logistic Regression Classifier 인데요, 먼저 기본이 되는 선형회기(linear regression)에 대해 간단히 알아보기로 하겠습니다. D차원의 N개의 데이터를 가지는 입력 메트릭스 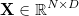 와 각 데이터에 따른 하나의 실수값을 가지는 출력 벡터
와 각 데이터에 따른 하나의 실수값을 가지는 출력 벡터 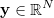 가 있을 때, 선형회기는 입력과 출력 사이의 선형변환 관계를 나타내는 D차원의
변수값
가 있을 때, 선형회기는 입력과 출력 사이의 선형변환 관계를 나타내는 D차원의
변수값 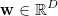 를 구하는 것입니다.
를 구하는 것입니다.
이 문제는 다음과 같은 loss function을 최소화 하는 w를 구하는 문제로, 최소자승법을 사용하여 간단히 구할 수 있습니다.
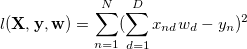
하지만, X의 값 전체를 미리 알 수 없을 때, 또는 X의 값이 너무 커서 메트릭스 연산이 가능한 메모리 용량을 넘어서게 될때는 최소자승법으로
구할 수 없습니다. 이런 경우 수치해석적인 방법으로 풀수가 있는데요, 이를 online learning 이라고 하며, 가장 널리 사용되는
방법으로는 gradient descent algorithm 이 있습니다. 뉴럴네트워크 모델의 기본이 되는 방법이기도 하며, 선형회기 문제에서는
위의 loss function이 하나의 global optima를 가지므로 gradient descent 방법으로 최적의 해를 찾을 수
있습니다.
gradient descent 방법은 간단하게 다음과 같이 설명할 수 있습니다. 모든 w 값을 임의의 값으로 초기화한 다음, 각 데이터가 들어올
때마다, 현재 w값의 변화에 따른 loss function의 변화량 (gradient)를 계산합니다.
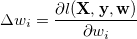
그 이후에, 각 w 값을 다음 업데이트 룰에 따라 갱신합니다. 여기서  값은 learning rate이라고 하며 1보다 작은 값을 취합니다.
값은 learning rate이라고 하며 1보다 작은 값을 취합니다.
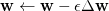
위의 과정을 w값이 특정 값에 수렴할때까지 모든 데이터에 대해서 반복적으로 수행합니다. 참고로, 데이터 하나마다 w값을 업데이트 하는 것을
incremental learning 이라고 하고, 모든 데이터에 대한 gradient를 모았다가 한번에 w값을 갱신하는 방법을 batch learning, 그리고 한정된 수 만큼의 데이터에 대한 gradient를 모았다가 갱신하는 방법을 mini-batch learning 이라고
합니다. 자세한 내용은 Sarle, Warren, S(2002)의 Neural Network FAQ2를 참고하세요.
Logistic Regression Model
앞에서 알아본 Logistic Regression은 실수값을 출력으로 갖는 회기분석법입니다. 하지만 이를 이용해서 분류기로 사용할 수 있는데요.
출력값이 각 데이터의 라벨을 나타내고자 할 때, regression의 출력은 각 카테고리가 라벨이 될 확률값이 됩니다. 0과 1사이의 확률값을
출력으로 나타내는 regression 모델을 만들기 위해서, logistic function이라고 부르는 비선형 함수를 위에서 본 linear
regression 뒤에 붙이면 되는데요. 수식으로 표현하면 다음과 같이 두 단계로 표현됩니다.
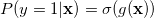
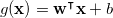
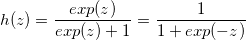
앞의 예제에서 알아본 Caffe의 layer를 사용하면, 위의 선형 변환, 비선형 logistic 함수로 이루어진 두 단계를 두 층의
layer를 이용하여 나타낼 수 있습니다. 바로 아래와 같은 inner product layer 와 softmax loss layer 입니다.
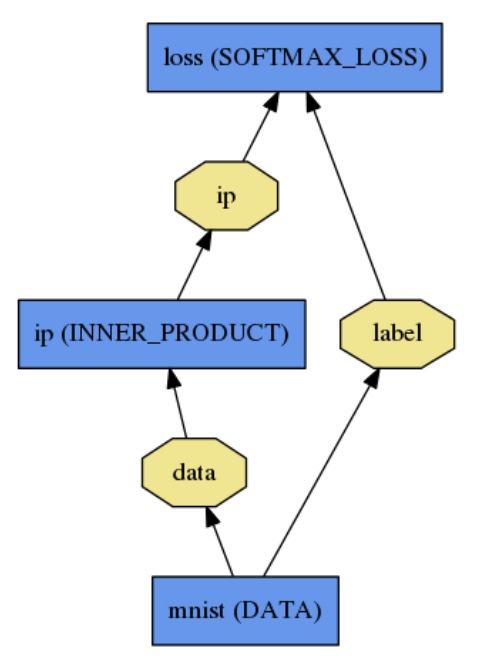
위의 그래프에서 파란색 사각형은 layer를, 노란색 팔각형은 blob을 나타내는데요, inner product (ip) layer는 데이터를
bottom blob으로 하고, 위의 수식에서 g(x)값인 ip라는 top blob을 생성합니다. ip layer 안에 파라미터 blob으로는
선형변환을 나타내는 w와 b를 가지고 있습니다. 여기서 multi-class인 경우 (즉 MNIST 데이터는 10개의 class), class의
갯수(m)만큼의 ip 값을 출력 가지는데요. 따라서 w는 dxm 의 메트릭스로 표현이 됩니다.
softmax loss layer는 m차원의 ip 값을 첫 번째 bottom blob으로 하고 label을 두 번째 bottom blob으로
합니다. ip값은 각 class 별로 위의 h(z) 단계를 거쳐서 각 class에 대한 추정 확률을 계산하게 되구요, 그 중에서 가장 큰 값을
가지는 class가 바로 추정된 label 값이 됩니다. 이렇게 softmax loss layer에서 추정된 label과 MNIST
training data에서 정의된 label을 비교하여 loss를 계산합니다.
Forward pass and Backward pass
앞에 강의에서 layer는 forward pass, backward pass를 계산할 수 있다는 것을 배웠는데요, LogReg 모델에서 두
과정이 어떻게 계산이 되는지 알아보겠습니다.
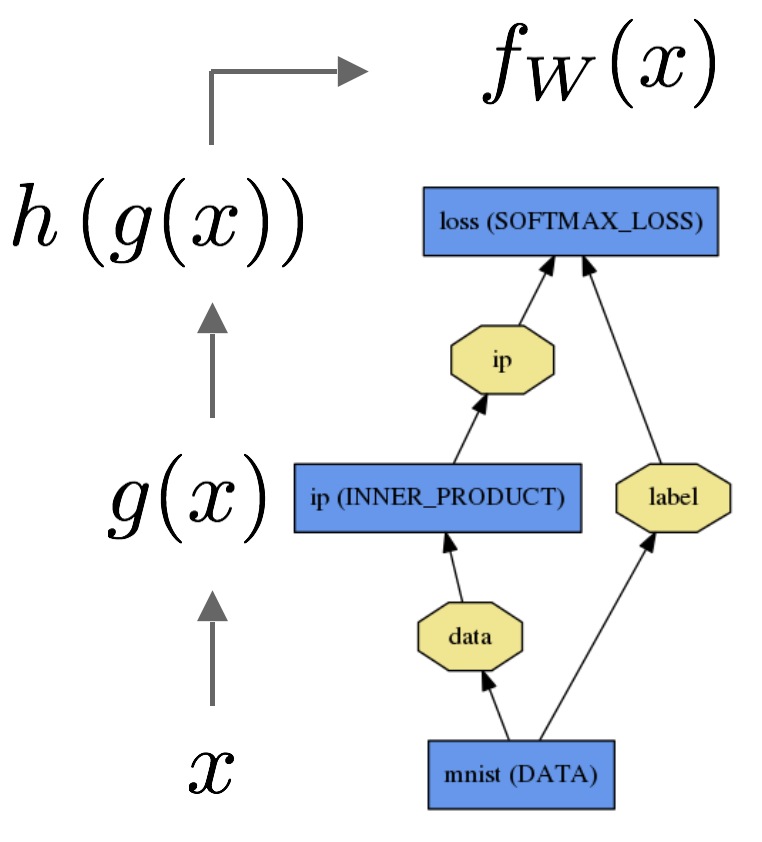
첫 번째 그림은 앞서 설명한 데이터로부터 g(x), h(z) 두 식을 이용하여 loss를 구하는 forward 과정을 나타내는 그림입니다.
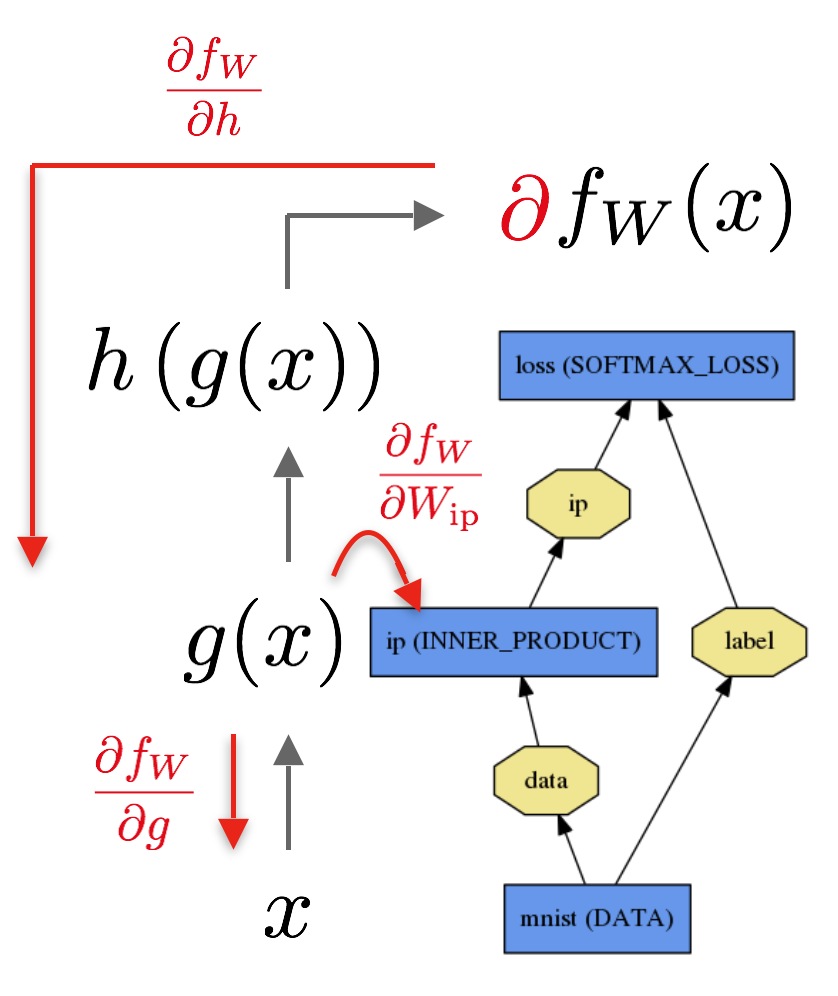
여기서 두 번째 그림인 backward 과정을 눈여겨 볼까 합니다. 먼저 forward pass로 부터 loss 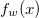 가 구해진 이후에, 각 class 별 확률값인 h(z)에 따른 loss의 변화량 softmax gradient(
가 구해진 이후에, 각 class 별 확률값인 h(z)에 따른 loss의 변화량 softmax gradient(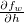 )를 계산할 수 있습니다. MNIST dataset 인 경우에는 1개의 loss로부터 10개의 가 구해지겠죠.
)를 계산할 수 있습니다. MNIST dataset 인 경우에는 1개의 loss로부터 10개의 가 구해지겠죠.
각 softmax gradient로부터 입력 데이터의 차원수 만큼의 weight 값들의 gradient가 계산될 수 있는데요. 이를 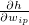 라고 하면, 각 weight에 따른 loss의 변화량은 다음과 같은 chain
rule 에 의해 구할 수 있습니다.
라고 하면, 각 weight에 따른 loss의 변화량은 다음과 같은 chain
rule 에 의해 구할 수 있습니다.
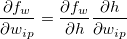
이렇게 얻어진 각 weight의 gradient는 앞에서 소개한 weight update rule (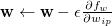 )에 의해 weight를 갱신합니다.
)에 의해 weight를 갱신합니다.
Caffe의 layer에서 Backward() 함수는 이렇게 계산된 각 weight의 gradient (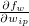 )를 layer의
)를 layer의 diff 변수에 저장합니다. 그리고 Update() 명령을 통해 weight update rule을 실행하게 됩니다.
Example source code
앞에서 설명한 LogReg 모델을 Caffe의 layer를 이용해서 직접 구현해보고, MNIST training dataset을 이용해 학습하고
test dataset을 통해 모델의 예측 정확도를 측정해 봅시다. 먼저 깃헙에 있는 ex5_logreg_mnist 준비합니다. ex_logreg_mnist.cpp 파일의 main 함수를 보면서 설명을 구현 과정을 설명 하겠습니다.
Data layer
위의 LogReg 모델에서 가장 아래에 있는 layer는 data layer 입니다. 이 레이어의 역할은 lmdb 또는 leveldb로 정의된
데이터 파일을 읽어와서 blob으로 저장하고, top blob으로 입력 데이터 x와 출력 데이터 y을 분리해서 두 개의 top blob으로
생성합니다. 또한 제한된 메모리에 다 저장하지 못하는 양이 많은 데이터인 경우를 위해, batch_size 만큼의 데이터를 렌덤하게 골라서
한정된 크기의 blob을 만들 수도 있구요, 데이터를 출력하기 전에 스케일링 하기도 합니다.
앞선 강좌에서 layer를 정의하는 방법은 알아보았으니, data layer의 경우에만 해당하는 레이어 파라미터 부분을 살펴보도록 하겠습니다.
blob_top_data_vec.push_back(blob_data);
blob_top_data_vec.push_back(blob_label);
LayerParameter layer_data_param;
DataParameter* data_param = layer_data_param.mutable_data_param();
data_param->set_batch_size(64);
data_param->set_source("caffe/caffe/examples/mnist/mnist_train_lmdb");
data_param->set_backend(caffe::DataParameter_DB_LMDB);
TransformationParameter* transform_param =
layer_data_param.mutable_transform_param();
transform_param->set_scale(1./255.);
DataLayer<Dtype> layer_data(layer_data_param);
layer_data.SetUp(blob_bottom_data_vec, blob_top_data_vec);
우선 DataParameter는 데이터셋의 위치와 타입, batch 크기를 결정합니다. 여기서는 앞에 MNIST 강좌에서 설치한 mnist lmdb 경로를 지정해줍니다. 먼저 모델을 학습하기 위해 사용하는 training data로 data layer를 만듭니다. TransformationParameter는 데이터를 스케일링 할때 사용합니다. 여기서 MNIST 데이터는 0~255 사이의 값이므로, 0~1로 정규화 하였습니다.
Inner product (ip) layer
두 번째로 ip layer를 만들어보겠습니다. ip layer는 data layer의 top blob인 blob_data 를 bottom blob으로 하고, blob_top_ip 를 생성합니다.
vector<Blob<Dtype>*> blob_bottom_ip_vec;
vector<Blob<Dtype>*> blob_top_ip_vec;
Blob<Dtype>* const blob_top_ip = new Blob<Dtype>();
blob_bottom_ip_vec.push_back(blob_data);
blob_top_ip_vec.push_back(blob_top_ip);
LayerParameter layer_ip_param;
layer_ip_param.mutable_inner_product_param()->set_num_output(nClass);
layer_ip_param.mutable_inner_product_param()->mutable_weight_filler()->set_type(
"xavier");
layer_ip_param.mutable_inner_product_param()->mutable_bias_filler()->set_type("c
onstant");
InnerProductLayer<Dtype> layer_ip(layer_ip_param);
layer_ip.SetUp(blob_bottom_ip_vec, blob_top_ip_vec);
ip layer의 출력은 class 갯수(10) 만큼이며, ip layer의 setting parameter를 통해 weight 및 bias 값을 xavier 방법을 이용하여 초기화 하였습니다.
Softmax loss layer
마지막으로 softmax loss layer를 세팅합니다. 위에 그림에서 보시는데로 ip layer의 top blob과 data layer의 blob_label 을 입력으로 하고, loss 값을 blob_top_loss blob에 출력으로 저장합니다.
vector<Blob<Dtype>*> blob_bottom_loss_vec;
vector<Blob<Dtype>*> blob_top_loss_vec;
Blob<Dtype>* const blob_top_loss = new Blob<Dtype>();
blob_bottom_loss_vec.push_back(blob_top_ip);
blob_bottom_loss_vec.push_back(blob_label);
blob_top_loss_vec.push_back(blob_top_loss);
LayerParameter layer_loss_param;
SoftmaxWithLossLayer<Dtype> layer_loss(layer_loss_param);
layer_loss.SetUp(blob_bottom_loss_vec, blob_top_loss_vec);
Forward and backward pass
드디어 LogReg 모델이 만들어졌습니다. 이제는 이 모델을 학습할 차례인데요, 학습은 위에서 간략히 설명한것 처럼 forward,
backward, update 이 세 과정을 loss값이 수렴할 때까지 반복합니다. 여기서는 간단히 nIter 만큼 for 문으로
반복하도록 하겠습니다.
for(int n=0;n<nIter;n++){
// forward
layer_data.Forward(blob_bottom_data_vec, blob_top_data_vec);
layer_ip.Forward(blob_bottom_ip_vec, blob_top_ip_vec);
Dtype loss = layer_loss.Forward(blob_bottom_loss_vec, blob_top_loss_vec);
cout<<"Iter "<<n<<" loss "<<loss<<endl;
// backward
vector<bool> backpro_vec;
backpro_vec.push_back(1);
backpro_vec.push_back(0);
layer_loss.Backward(blob_top_loss_vec, backpro_vec, blob_bottom_loss_vec);
layer_ip.Backward(blob_top_ip_vec, backpro_vec, blob_bottom_ip_vec);
// update weights of layer_ip
Dtype rate = 0.1;
vector<shared_ptr<Blob<Dtype> > > param = layer_ip.blobs();
caffe_scal(param[0]->count(), rate, param[0]->mutable_cpu_diff());
param[0]->Update();
}
실행결과를 보면 다음과 같이 iteration이 진행될 수록 loss값이 줄어드는 것을 볼 수 있습니다.
Iter 0 loss 2.30016
Iter 1 loss 2.12608
Iter 2 loss 2.19263
Iter 3 loss 1.93675
Iter 4 loss 1.85901
Iter 5 loss 1.75871
Iter 6 loss 1.68629
Iter 7 loss 1.68272
Iter 8 loss 1.64218
Iter 9 loss 1.72062
Iter 10 loss 1.57099
...
Iter 100 loss 0.501477
Iter 101 loss 0.614108
Iter 102 loss 0.401204
Iter 103 loss 0.421984
Iter 104 loss 0.523702
Iter 105 loss 0.487135
Iter 106 loss 0.750514
Iter 107 loss 0.576815
Iter 108 loss 0.639771
Iter 109 loss 0.678125
Iter 110 loss 0.506516
...
Iter 1000 loss 0.343701
Iter 1001 loss 0.336663
Iter 1002 loss 0.595591
Iter 1003 loss 0.215748
Iter 1004 loss 0.34533
Iter 1005 loss 0.305032
Iter 1006 loss 0.18276
Iter 1007 loss 0.400066
Iter 1008 loss 0.132792
Iter 1009 loss 0.290646
Iter 1010 loss 0.419739
...
Iter 9990 loss 0.449115
Iter 9991 loss 0.549783
Iter 9992 loss 0.229075
Iter 9993 loss 0.172593
Iter 9994 loss 0.322345
Iter 9995 loss 0.287676
Iter 9996 loss 0.256037
Iter 9997 loss 0.263619
Iter 9998 loss 0.274014
Iter 9999 loss 0.346595
여기서는 batch 갯수를 64개로 하였는데요, 그 갯수만큼 data layer가 임의의 데이터를 추출하기 때문에 60000개의 MNIST
training data를 모두 다 학습하는데 사용하기 위해서는 최소 10000번의 iteration이 필요합니다. 하지만 보시는데로
1000번에서 9999번 사이에는 training loss의 감소가 유의미하게 보이지 않습니다.
MNIST label prediction
이제 학습된 모델을 주어진 MNIST test data에 적용하여 라벨을 예측해보도록 합시다. 위에서 만들어진 LogReg 모델을 새로운
데이터셋에 맞게 수정을 해야 하는데요, 학습된 weight, bias 값은 유지하면서 레이어를 재조정하는 Reshape() 기능을
사용합니다.
먼저 data layer를 새로 만듭니다. 이번에는 mnist test lmdb를 입력으로 하고, batch size를 10000개로
조정합니다.
testdata_param->set_batch_size(10000);
testdata_param->set_source("caffe/caffe/examples/mnist/mnist_test_lmdb");
testdata_param->set_backend(caffe::DataParameter_DB_LMDB);
그리고 새로운 data layer의 출력을 입력으로 받는 layer_ip와 layer_loss를 reshaping 합니다.
layer_ip.Reshape(blob_bottom_ip_test_vec, blob_top_ip_vec);
...
layer_loss.Reshape(blob_bottom_loss_test_vec, blob_top_loss_vec);
마지막으로, 이전 강좌에서 다루었던 argmax layer를 ip layer위에 붙여서 label prediction 값을 확인해 보도록
하겠습니다.
blob_bottom_argmax_vec.push_back(blob_top_ip);
blob_top_argmax_vec.push_back(blob_top_argmax);
...
layer_argmax.SetUp(blob_bottom_argmax_vec, blob_top_argmax_vec);
Prediction은 새로 재구성된 layer들의 forward 과정을 통해 결과를 얻을 수 있습니다.
layer_testdata.Forward(blob_bottom_testdata_vec, blob_top_testdata_vec);
layer_ip.Forward(blob_bottom_ip_test_vec, blob_top_ip_vec);
layer_argmax.Forward(blob_bottom_argmax_vec, blob_top_argmax_vec);
Dtype loss = layer_loss.Forward(blob_bottom_loss_test_vec, blob_top_loss_vec);
Result
이제 10000개의 test data 중에 얼마나 정확하게 정답을 맞추었는지 한번 보도록 하겠습니다.
for (int n = 0; n<blob_testlabel->count();n++){
cnt ++;
Dtype* label_data = blob_testlabel->mutable_cpu_data();
int truelabel = label_data[n];
Dtype* prediction_data = blob_top_argmax-> mutable_cpu_data();
int predictedlabel = prediction_data[n];
if(truelabel == predictedlabel){
correct++;
}
}
cout << "Accuracy: " << correct <<"/" << cnt <<endl;
iteration 횟수에 따라서 test loss와 accuracy 를 살펴보면 다음과 같습니다.
nIter: 100
loss: 0.581051
Accuracy: 8580/10000
nIter: 1000
loss: 0.335188
Accuracy: 9060/10000
nIter: 5000
loss: 0.288763
Accuracy: 9199/10000
nIter: 10000
loss: 0.281142
Accuracy: 9230/10000
nIter: 20000
loss: 0.275626
Accuracy: 9235/10000
nIter: 30000
loss: 0.276298
Accuracy: 9228/10000
앞에서 training loss만 살펴보았을때는 1000번부터 10000번 사이에는 loss 값이 정체되어 있는것 처럼 보였습니다만, test
loss를 살펴보니, 20000번까지 유의미한 차이가 있음을 알 수 있습니다. 30000번일때는 오히려 그 결과가 좋지 않음을 보아 over-
fitting이 되었음을 알 수 있습니다. 결국 training loss는 1000번쯤에서 수렴한것처럼 보여도 under-fitting 되어
있었고, 60000개의 training dataset을 모두 셈플링한 20000번 가까이에서 최적의 모델이 학습되었음을 알 수 있습니다. 이번
예제를 통해 다시 한번 cross validataion의 필요성을 알 수 있었네요.
다음 강좌에서는 Convolutional Neural Network 모델을 구현해보고 MNIST 데이터로 학습하고 결과를 비교해 보겠습니다.
그리고 python을 이용하여 cross validation 및 그 결과를 확인해보는 시간도 가지도록 하겠습니다.