네 번째 예제에서는 Layer 구조와 기능에 대해 알아봅니다.
Edit me
By koosy on 2015.12.15
'layer' in Caffe
지난 강좌에서는 Caffe의 기본 데이터 구조인 blob에 대해서, 그리고 MNIST 데이터셋에 대해서 알아보았습니다. 이제는 본격적인 뉴럴넷 모델을 만들기 위한 핵심 빌딩블록인 layer에 대해 알아볼텐데요. 이번 시간에는 argmax layer 간단한 예를 통해 layer와 blob의 관계를 알아보고, 다음 시간에는 layer 구조를 이용하여 MNIST 데이터셋을 한번 학습해 보도록 하겠습니다.
Layer란?
caffe 모델에서 blob이 데이터 구조라면 layer는 연산자에 해당합니다. 아래 보시는 그림처럼 blob을 입력으로 받아서 다양한 연산을
수행하고 그 결과를 blob으로 저장해서 내보냅니다. 쉽게 생각해서 필터 역할을 한다고 보시면 됩니다.
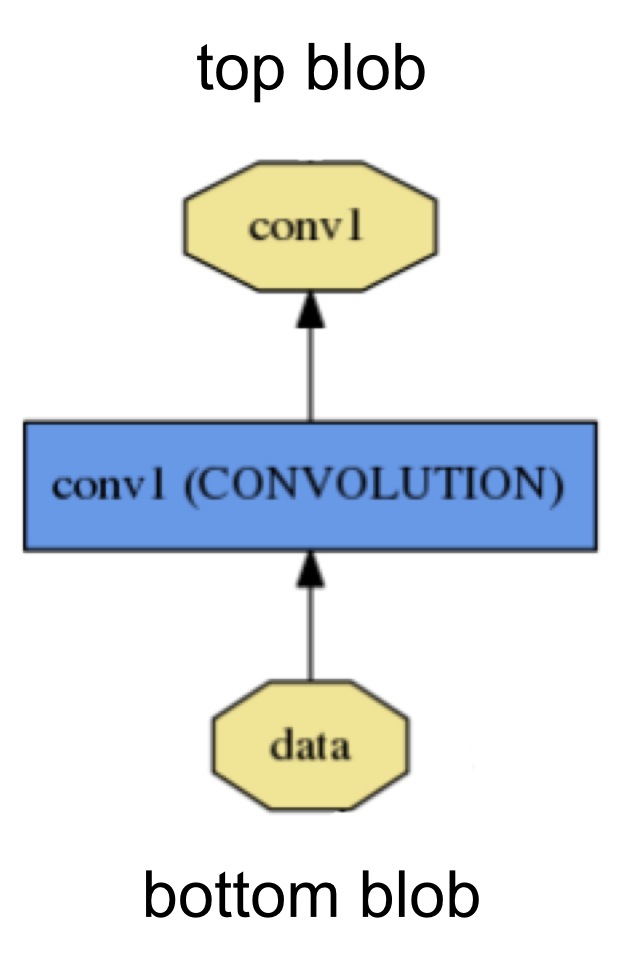
caffe는 다양한 종류의 layer를 지원하는데요, 예를 들어 convolution filter, pooling layer, inner
product layer, rectified-linear layer, sigmoid layer, transformations,
normalize, loss functions 등등 아주 많이 있구요. caffe 커뮤니티가 발전함에 따라 layer의 종류도 늘어나고
있습니다. 또한 오픈소스이기 때문에 자신에게 필요한 layer를 설계하고 구현할 수도 있습니다.
layer에 대한 설명은 caffe 공식 튜토리얼 페이지 중에
layer에서 찾아보실 수 있습니다. 하지만
더 좋은 방법은 직접 소스코드를 살펴보는것이겠죠? 바로 오픈소스 코드 중에 각 layer의 기능이 정의된
헤더파일들과
소스파일들를 보면 caffe에서
사용할 수 있는 다양한 layer들의 구현 코드를 다 볼 수 있습니다. 대부분의 layer들이 CPU에서 구현된 .cpp 파일과 GPU에서
구현된 .cu 파일을 가지고 있습니다.
layer.hpp
layer를 어떻게 생성하고 사용하는지는 아래에 있는 argmax layer 예제를 통해 자세히 살펴볼텐데요. 그 전에 간단히 모든
layer들의 부모클래스인
layer.hpp를
한번 같이 보면서 layer의 기본 구조 및 사용법에 대해 감을 잡아보도록 하죠. 참고로 caffe는 소스코드가 아주 체계적으로 작성되어 있어서
따로 문서화의 필요성을 못느낄 정도입니다. 소스코드를 보면서 배우고 익히는 재미도 있구요.
먼저 Layer class의 생성자를 먼저 보면요. LayerParameter 타입의 파라미터 값을 인자로 받습니다.
explicit Layer(const LayerParameter& param)
이 param값은 각 layer마다 특수하게 요구하는 파라미터들입니다. 기존 layer를 사용하기 위해서는 그 layer가 지원하는 그리고
필요한 파라미터들이 무엇이 있는지 알아야 할텐데요. 그것은 proto
파일로 스크립트
형태로 정의되어 있습니다. 만약에 새로운 layer를 만들고 싶다고 하면, 여기 proto 파일에다가 필요한 파라미터들과 초기값을 정의하면
됩니다. 그러면 caffe를 컴파일할 때 새로 추가된 layer의 파라미터를 정의한 헤더파일이 자동으로 생성됩니다. 자세한건 아래
argmax 예제에서 더 알아보도록 하죠.
layer를 생성한 다음에는 그 layer를 통해 계산되는 입출력 blob을 알려주어야 합니다. 미리 생성된 bottom blob, top
blob들을 SetUp 함수를 통해 넘겨주면 됩니다.
void SetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top)
여기서 bottom/top blob들이 각각 vector형태로 정의된것을 볼 수 있는데요. 즉, 입출력으로 한 개 이상의 blob들이
layer로 들어가고 나올수 있다는 말입니다. 이러한MIMO형태의 layer를 이용하여 복잡한 네트워크 모델을 구성할 수 있습니다.
이 SetUp 함수를 보시면 몇 가지 명령이 실행되는데요, 그 중에 아래 LayerSetUp과 Reshape은 각 layer들이
특수하게 수행하는 layer 초기화 과정으로, virtual로 선언되어 있어서 각 자식 class에서 재정의할 수 있습니다.
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {}
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) = 0;
이번에 보실 두 가지 함수는 가장 중요한 layer의 계산 기능을 담당하는데요. 바로 Forward와 Backward입니다.
inline Dtype Forward(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
Forward는 bottom blob에서 top blob으로 layer에서 정의된 연산을 수행합니다. 여기서 입력으로 또다시
bottom/top blob을 정의해야 하는데요. 이전에 SetUp에서 정의했는데 왜 또 하는가 하면, layer를 다른 데이터에 이식할 수
있게 하기 위해서입니다. 각 layer는 정의에 필요한 파라미터 값 외에도 연산에 필요한 변수들(예를 들어 inner product layer의
weight값)을 가지고 있는데요. 이렇게 미리 구성된 또는 학습된 layer를 다른 데이터에 적용할 수 있기 때문에 모델을 훈련 후 새로운
데이터를 예측하는데 사용될 수 있습니다.
Backward는 Forward와는 반대로 top blob에서 bottom blob으로 연산이 진행됩니다. 즉 네트워크 모델을 훈련하는
기본 메커니즘인 역전파(backpropagation) 알고리즘이 동작하는 것이죠.
inline void Backward(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom);
아시다시피 각 학습변수들의 변화량이 최종 출력단의 loss에 미치는 영향은 chain rule에 의해 각 변수별로 분리되어서 계산될 수
있습니다. 그리고 gradient decent 알고리즘에 의해서 loss가 작아지는 방향과 일치하도록 각 학습변수를 증감하는 과정을 반복하며
최적의 변수값들이 학습되는 것이죠. 이 과정에서 Backward 함수는 top blob의 변화량에 대한 bottom blob의 변화량을
계산하고, bottom blob에 저장합니다. 이전에 언급했는지 모르겠지만, 각 blob에는 데이터(blob->cpu_data())의
변화량을 항상 저장하는 변수(blob.cpu_diff())가 따로 있습니다. 결과적으로 Backward과정을 통해서 이 diff()
변수값이 업데이트 되는 것입니다.
propagate_down 벡터변수는 bottom blob이 여러개 있을때 역전파를 적용할 blob과 적용하지 않을 blob을 구분하는
역할을 합니다.
argmax layer
자, 그럼 이제 실제 예제코드를 보면서 layer를 사용해보도록 할게요. 여기서는 layer의 기본 사용법을 익히기 위해 한 층의 argmax
layer를 정의하고 SetUp()과 Forward() 기능만 다루도록 하겠습니다. 대신 다음번 예제에서는 두 층의 layer를
만들고, Backward()기능까지 합하여 Logistic Regression Classification을 구현해 보는걸 하겠습니다.
Source code
먼저 깃헙에서 ex4_layer
파일들을
준비하시고, main.cpp 파일을 열어봅니다. 이 예제에서는 임의로 20차원의 값을 가지는 10개의 데이터(10x20x1x1)를
bottom blob에 생성하고, 각 데이터 별로 가장 큰 값을 가지는 차원의 수를 찾는 argmax 문제입니다.
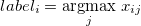
첫 번째로, 비어있는 top blob과 GaussianFiller를 이용하여 bottom blob을 생성합니다.
Blob<Dtype>* blob_top = new Blob<Dtype>();
Blob<Dtype>* blob_bottom = new Blob<Dtype>(10, 20, 1, 1);
FillerParameter filler_param;
GaussianFiller<Dtype> filler(filler_param);
filler.Fill(blob_bottom);
GaussianFiller 역시 FillerParameter로 정의된 값을 가지는데요, 여기서는 아무 값도 정의하지 않은 기본값을
사용합니다. 그럼 기본값은 어떻게 정의가 되어 있는지 알 수 있을까요? caffe에서는 모든 파라미터 정의는 위에서 본 proto파일에 정의가
되어 있습니다. 그 중에서 FillerParameter 부분 을 보면, GaissianFiller에 대한 초기값은 아래처럼 설정되어 있는 것을
찾을 수 있습니다.
optional float mean = 5 [default = 0]; // the mean value in Gaussian filler
optional float std = 6 [default = 1]; // the std value in Gaussian filler
즉, 평균 0 표준편차 1인 정규분포에서 임의로 값을 셈플링해서 bottom blob에 채워 넣습니다.
그 다음에는 layer에 bottom/top blob들을 정의하기 위해서 blob 벡터를 만듭니다. 여기서는 bottom/top blob이
하나씩 밖에 없네요.
vector<Blob<Dtype>*> blob_bottom_vec;
vector<Blob<Dtype>*> blob_top_vec;
blob_bottom_vec.push_back(blob_bottom);
blob_top_vec.push_back(blob_top);
이제 argmax layer를 만들어 봅시다. 앞에서 살펴보았듯이, 모든 layer는 LayerParameter타입의 값을 인자로 받습니다.
여기서는 ArgMaxLayer를 정의해야 하기 때문에, ArgMaxParameter 타입의 파라미터 값들을 셋팅하고,
layer_param에 저장합니다.
LayerParameter layer_param;
ArgMaxParameter* argmax_param = layer_param.mutable_argmax_param();
argmax_param->set_out_max_val(true); // two channel: 0 arg, 1 max_val
ArgMaxLayer<Dtype> layer(layer_param);
layer.SetUp(blob_bottom_vec, blob_top_vec);
ArgMaxParameter가 무슨 변수들을 가지는지는 역시 proto 파일에서 해당부분을 살펴보면 알 수 있습니다. 여기서는
out_max_val값을 true로 설정했는데요, 이는 top blob에 argmax 값 외에도 max값도 저장한다는 의미입니다. 즉
top blob의 체널수가 2가 됩니다.
그럼 이제 blob들이 잘 셋팅이 되었는지 확인해봅시다.
cout<<"blob_top_num:"<<blob_top->num()<<endl;
cout<<"blob_bottom_num:"<<blob_bottom->num()<<endl;
cout<<"blob_top_channels:"<<blob_top->channels()<<endl;
앞에서 본것처럼 bottom blob은 number가 10, channel이 20으로 우리가 생성했었고, top blob은 크기를 할당하지
않았었는데요, argmax layer를 정의하면서 top blob은 이에 맞게 reshape이 되었습니다. 즉, number는 10으로 같고,
channel은 2가 되는데요, 0번 channel은 argmax값이, 1번 channel은 max값이 저장이 됩니다.
blob_top_num:10
blob_bottom_num:10
blob_top_channels:2
마지막으로 동일한 bottom/top blob으로 Forward() 연산을 수행합니다.
layer.Forward(blob_bottom_vec, blob_top_vec);
결과 확인
이제 드디어 argmax layer의 결과를 확인할 시간입니다. 아래 코드에서 top blob에 저장된 data들을 확인해보고, bottom
blob에 저장된 값을 실제로 보면서 비교해보았는데요. 이 중에 눈여겨 보실것은, 각 blob에 있는 데이터에 접근할때 offset()
함수를 사용하면, 더 직관적으로 데이터가 어디에 있는지 알 수 있습니다.
int max_ind;
Dtype max_val;
int num = blob_bottom->num();
int dim = blob_bottom->count() / num;
for (int i = 0; i < num; ++i) {
max_ind = top_data[blob_top->offset(i,0,0,0)];
max_val = top_data[blob_top->offset(i,1,0,0)];
cout<<"max_ind:"<<max_ind<<endl;
cout<<"max_val:"<<max_val<<endl;
for (int j = 0; j < dim; ++j) {
cout<<bottom_data[i * dim + j]<<" ";
}
cout<<endl;
}
예상대로 아래와 같은 결과를 얻었습니다.
max_ind:16
max_val:1.60021
1.02345 0.644398 1.35707 1.20215 -1.22354 -0.144769 -1.6884 0.206628 0.827454
-0.777199 1.17707 -2.14505 0.168406 0.708166 1.14211 0.710544 1.60021 -0.267681
-0.427183 -0.931403
max_ind:10
max_val:1.8514
-0.890813 1.63484 0.423656 0.776203 -0.608275 1.11862 -0.813977 0.780552
0.566104 -0.23574 1.8514 0.16717 -0.205421 -1.00947 0.978151 1.17841 -0.676652
-0.538731 0.94863 -0.284807
max_ind:16
max_val:2.40903
0.570297 -1.1183 -0.841836 -1.3256 -1.55505 -1.11276 0.103234 0.483888 0.851208
0.872319 0.0651206 -1.37326 -0.618498 -0.251582 -1.39677 0.545281 2.40903
-1.05168 -3.26618 0.370113
max_ind:10
max_val:1.50859
0.493125 -0.366034 0.564747 0.177232 -0.14659 0.160106 -0.719022 1.39956
-1.41528 0.221579 1.50859 -0.843022 1.06157 0.191537 -0.902494 0.984655 0.784134
-0.144773 -1.13056 -1.03991
max_ind:13
맺음말
이번 시간에는 caffe의 layer에 대한 기본적인 설명 및 간단한 예를 통해 그 사용법을 알아보았습니다. 또한 caffe의 proto파일을
통해서 각 layer또는 filler를 설정하기 위한 파라미터들이 어떻게 정의가 되는지도 찾아볼 수 있었습니다. 지금까지 알아본 blob, layer를 통해 더 복잡한 네트워크 모델을 만들 준비가 되었는데요.
다음시간에는 두 층의 layer를 통해서 Logistic Regression Classification을 구현해보고, 이를 MNIST
dataset에 적용해서 훈련해보도록 하겠습니다.